
Whether you’re transitioning from another data platform or deepening your understanding of cloud-native warehouses, these Master Snowflake Architecture: Interview Questions & Answers will give you a strong foundation. Each question highlights your grasp of Snowflake’s unique features like virtual warehouses, micro-partitioning, caching, and query optimization.
Q1. What are the three core layers of Snowflake’s architecture?
Snowflake’s architecture is built on three layers that work together seamlessly in the cloud. While each layer has a distinct role, the Cloud Services Layer acts as the brain of Snowflake—orchestrating operations, optimizing performance, and managing security. Here’s a breakdown of each layer with real-world analogies:
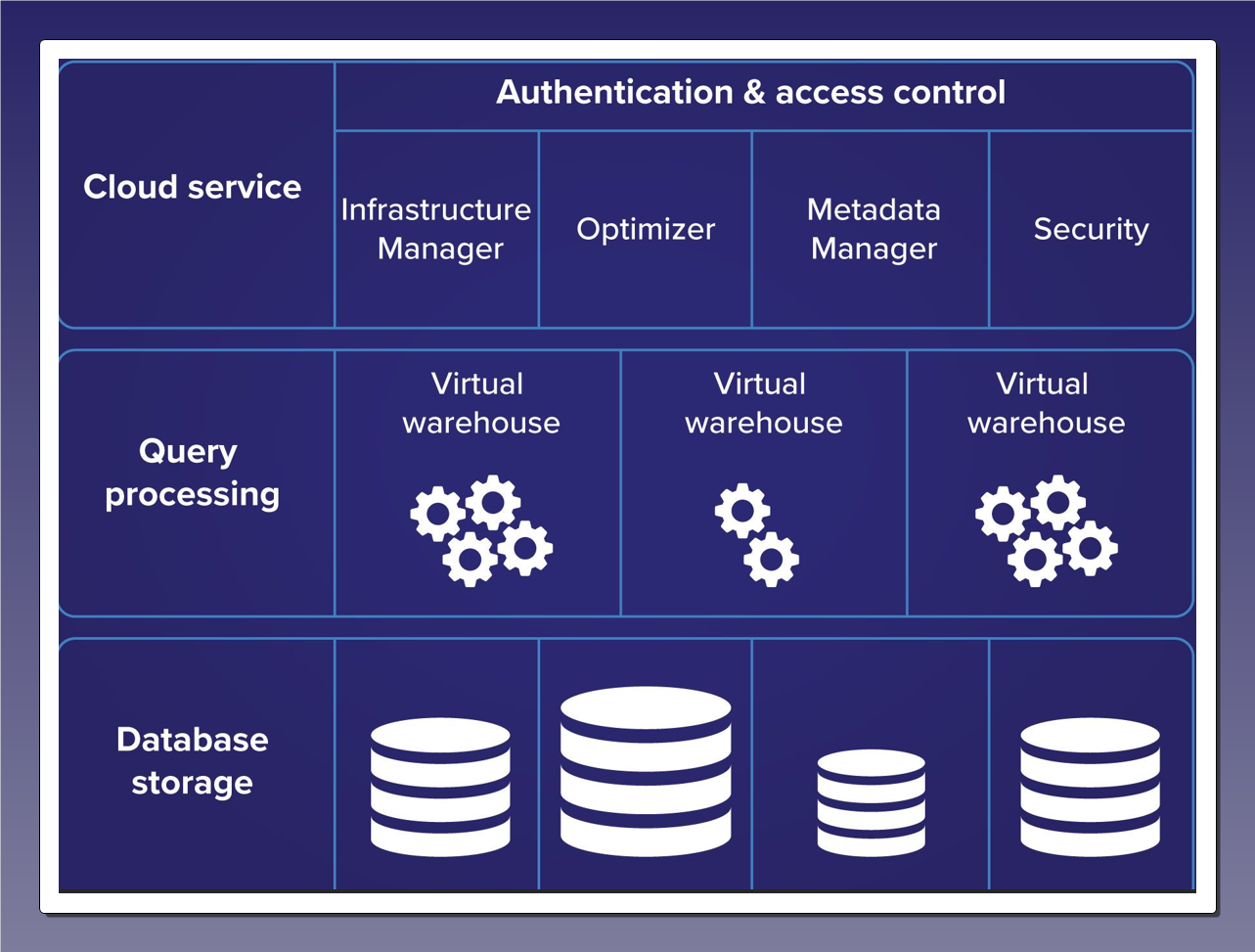
Key Concepts & Architecture | Snowflake Documentation
A. Database Storage Layer (The Warehouse)
Role: Stores all structured and semi-structured data (tables, JSON, Parquet, etc.) in an optimized, compressed, and columnar format.
Role: Stores all structured and semi-structured data (tables, JSON, Parquet, etc.) in an optimized, compressed, and columnar format.Key Features:
✔ Micro-partitions – Data is split into small, manageable chunks and stores in micro-partitions (50-500MB) for efficient scanning.
✔ Automatic optimization – Snowflake handles compression, clustering, and metadata management.
✔ Supports ACID transactions – Ensures data integrity even with concurrent users.
Example:
Imagine you’re storing customer transaction data for an e-commerce platform. When you load CSV files containing order information into Snowflake:
The data is automatically compressed and organized into micro-partitions
Metadata is created for each micro-partition (min/max values, count, etc.)
The data becomes immediately available for querying
B. Query Processing Layer (The Muscle)
Role: Executes queries using virtual warehouses (compute clusters).
Key Features:
✔ Independent scaling – Resize compute power on demand (XS to 6X-Large) and each warehouse operates independently (no resource contention)
✔ Massively Parallel Processing (MPP) – Splits queries across multiple nodes for speed.
✔ Zero contention – Different teams can run workloads without slowing each other down.
Example:
Your analytics team needs to run: A simple query: “How many customers made purchases last month?”
A complex query: “What’s the 30-day rolling average order value by customer segment?”
Snowflake will Allocate appropriate resources for each query
Use metadata to scan only relevant micro-partitions
Return results quickly by parallelizing the work across multiple nodes
C. Cloud Services Layer (The Brain)
The “orchestration” layer that coordinates all Snowflake operations. It manages infrastructure, security, metadata, and optimization.
Key Features:
✔ Authentication & Security – Manages user access, encryption, and role-based controls.
✔ Query Optimization – Acts like a query planner, determining the fastest execution path(skips irrelevant data via pruning).
✔ Metadata Management – Tracks data statistics to minimize scanning.
✔ Transaction Coordination – Ensures ACID compliance across concurrent operations.
Example:
Think of this as the air traffic control of Snowflake:
A user submits a query → Cloud Services checks permissions.
It analyzes the best way to execute the query → Optimizes the plan.
Assigns the task to the right virtual warehouse.
Monitors progress and returns results.
Why This Architecture Matters
✅ Separation of Storage & Compute – Scale independently, pay only for what you use.
✅ Automatic Optimization – The “brain” handles performance tuning.
✅ Multi-tenant Efficiency – Many users can query without slowdowns.
Q2. What is a virtual warehouse in Snowflake?
A virtual warehouse in Snowflake is an independent cluster of compute resources (CPU, memory, and temporary storage) used to execute SQL queries, load data, and perform other operations. Unlike traditional databases where compute and storage are tightly coupled, Snowflake allows you to scale compute resources up or down on demand without affecting stored data.
Key Features of a Virtual Warehouse
- On-Demand Scaling – You can resize (scale up/down) or suspend/resume warehouses as needed.
- Multiple Warehouses – Different teams can use separate warehouses to avoid resource conflicts.
- Pay-Per-Use Billing – You only pay when the warehouse is running.
- Auto-Suspend & Auto-Resume – Saves costs by shutting down when idle and restarting when needed.
Real-World Example: E-Commerce Analytics
Imagine you run an online store and use Snowflake for:
- Daily Sales Reports (small compute needs)
- Black Friday Analytics (heavy compute needs)
Scenario 1: Normal Day (Small Warehouse – X-Small)
- You use a small warehouse (X-Small, 1 server) to generate daily sales reports.
- It processes data quickly and shuts down automatically when done.
- Cost: Low, because minimal resources are used.
Scenario 2: Black Friday (Large Warehouse – 4X-Large)
- On Black Friday, traffic spikes, and you need real-time analytics.
- You scale up to a 4X-Large warehouse (16 servers) for faster processing.
- After processing, you scale back down to save costs.
- Cost: Higher during peak times, but only when used.
Scenario 3: Multiple Teams (Separate Warehouses)
- Marketing Team: Uses one warehouse for customer segmentation.
- Finance Team: Uses another warehouse for revenue calculations.
- No performance conflicts because each has dedicated resources.
Why Virtual Warehouses Are Powerful?
✅ Flexibility: Adjust compute power based on workload.
✅ Cost Efficiency: No over-provisioning; pay only for active usage.
✅ Concurrency: Multiple teams can run queries without slowdowns.
Q3. How Does Snowflake Handle Data Storage?
Snowflake’s storage system is designed for scalability, efficiency, and reliability, separating storage from compute to optimize performance and cost. Here’s how it works:
Key Features of Snowflake Storage
- Cloud-Based & Elastic
Data is stored in AWS S3, Azure Blob Storage, or Google Cloud Storage (depending on your cloud provider). Storage scales automatically—no manual partitioning or sharding required. - Columnar Storage Format
Data is stored in compressed, columnar format (like Parquet/ORC), making analytics queries faster. - Micro-Partitions (Automatic Clustering)
Tables are divided into small, contiguous blocks (micro-partitions, ~50-500MB each). Snowflake automatically clusters data based on usage patterns for optimal query performance. - Immutable & Versioned (Time Travel & Fail-Safe)
Changes create new versions (no in-place updates). Time Travel (1-90 days): Query historical data (e.g., undo accidental deletions). Fail-Safe (7 days): Snowflake’s backup for disaster recovery. - Zero-Copy Cloning
Create instant, storage-efficient clones of databases/tables (no extra storage cost until modified).
Real-World Example: Retail Company’s Sales Data
Scenario 1: Storing & Optimizing Data
A retail company loads 10TB of sales transactions into Snowflake. Snowflake: Compresses data (reducing storage costs by ~3-5x). Auto-partitions by date and product_category for fast filtering. Maintains metadata (like min/max values) to skip irrelevant data during queries.
Scenario 2: Time Travel for Recovery
A developer accidentally deletes last month’s sales data. Instead of restoring a backup, they use:
SELECT * FROM sales BEFORE(TIMESTAMP => '2024-05-01 12:00:00');
Retrieves the pre-deletion state instantly (no downtime).
Scenario 3: Zero-Copy Cloning for Testing
The analytics team needs a test copy of production data. Instead of duplicating 10TB:
CREATE TABLE sales_dev CLONE sales_prod;
Takes seconds, consumes no extra storage (only stores differences when modified).
Why Snowflake’s Storage is Powerful?
✅ Cost-Efficient: Pay only for actual storage used (compressed).
✅ High Performance: Columnar format + micro-partitions speed up queries.
✅ Reliable: Automatic backups (Time Travel & Fail-Safe).
✅ Scalable: No limits on data volume (petabyte-scale supported).
Q4. What Database Engine Does Snowflake Use?
Snowflake uses a custom-built, cloud-native SQL query engine designed specifically for its architecture. Unlike traditional databases that rely on existing engines (like MySQL, PostgreSQL, or Oracle), Snowflake’s engine is optimized for:
- Massively Parallel Processing (MPP)
- Distributes queries across multiple compute nodes (virtual warehouses) for fast performance.
- Example: Scanning 1TB of data takes seconds because work is split across many servers.
- Columnar Execution
- Processes data in columns (not rows), ideal for analytics.
- Example: Calculating total sales for a year only reads the
sales_amountcolumn, skipping irrelevant data.
- Push-Based Query Optimization
- Pushes computations to where the data resides (minimizing data movement).
- Example: Joins are optimized to run on the same nodes where data is stored.
- Native Support for Semi-Structured Data
- Directly queries JSON, Avro, Parquet, and XML without pre-processing.
- Example: Analyzing nested JSON log files with SQL (no ETL needed).
Why Not Use an Existing Engine?
Traditional databases (like PostgreSQL) weren’t built for:
- Cloud object storage (S3/Blob/GCS)
- Independent scaling of compute/storage
- Multi-cluster concurrency
Snowflake’s engine is purpose-built for these cloud advantages.
Real-World Example: Analytics Dashboard
A company runs a complex dashboard querying:
- Structured data (sales transactions)
- Semi-structured data (customer behavior JSON logs)
Snowflake’s engine:
- Scales compute (virtual warehouse) to run the query in parallel.
- Reads only required columns (columnar storage).
- Processes JSON natively without flattening.
- Returns results in seconds, even over petabytes.
Key Takeaway
Snowflake doesn’t use off-the-shelf databases—it’s a ground-up redesign for the cloud, combining:
- MPP speed (like Teradata)
- Columnar efficiency (like Redshift)
- Cloud elasticity (like BigQuery)
- SQL simplicity (like PostgreSQL)
This makes it uniquely powerful for modern data workloads
Q5. What File Format Does Snowflake Use to Store Data Internally?
Snowflake stores data in a proprietary, optimized columnar format designed specifically for its cloud architecture. While it resembles formats like Parquet or ORC, Snowflake’s internal storage is uniquely tailored for:
Key Characteristics
- Columnar Compression
- Data is stored by column (not row) and heavily compressed (typically 3-5x reduction).
- Example: A
sales_amountcolumn is stored contiguously with run-length encoding for efficiency.
- Micro-Partitions
- Data is split into small blocks (50–500MB uncompressed) with:
- Metadata (min/max values, counts) for fast pruning.
- Automatic clustering based on query patterns.
- Example: Filtering
WHERE date = '2024-01-01'skips irrelevant partitions instantly.
- Data is split into small blocks (50–500MB uncompressed) with:
- Immutable & Versioned
- Changes create new micro-partitions (no in-place updates).
- Enables Time Travel and zero-copy cloning.
- Cloud-Optimized
- Stored in cloud object storage (S3/Azure Blob/GCS) but not directly accessible to users.
How It Compares to Open Formats
| Feature | Snowflake Format | Parquet/ORC |
|---|---|---|
| Access | Proprietary (internal) | User-accessible |
| Compression | Higher (custom algorithms) | Standard |
| Partitioning | Auto-optimized | Manual tuning required |
| Time Travel | Built-in (1–90 days) | Not supported |
Real-World Example: Analytics Query
When you run:
SELECT product_id, SUM(sales) FROM transactions WHERE date BETWEEN '2024-01-01' AND '2024-01-31' GROUP BY product_id;
Snowflake:
- Reads only
product_idandsalescolumns (columnar efficiency). - Skips micro-partitions outside January 2024 (metadata pruning).
- Decompresses on-the-fly in the virtual warehouse.
Why This Matters?
✅ Faster Queries: Columnar + pruning = less I/O.
✅ Cheaper Storage: High compression reduces costs.
✅ Zero Maintenance: No manual tuning (unlike Parquet partitioning).
Unlike open formats, Snowflake’s storage is fully managed, letting you focus on queries—not file optimization.
Q6. What is the role of the cloud services layer in Snowflake?
The cloud services layer in Snowflake – that’s like the air traffic control tower of the whole system! Let me break it down in simple terms:
Think of Snowflake like a big airport:
- Your data is the airplanes (stored safely in the hangar/cloud storage)
- The virtual warehouses are the runways (where the actual work happens)
The cloud services layer is the control tower that manages everything behind the scenes:
- It’s the brains of the operation – When you run a query, this layer figures out the most efficient way to execute it across your warehouses.
- Handles all the admin stuff – Like:
- Logging you in (authentication)
- Keeping track of who can access what (security)
- Managing all your database objects (metadata)
- Optimizes everything automatically – It’s constantly:
- Caching frequently used data
- Tuning query performance
- Managing the micro-partitions in storage
- Coordinates the whole show – When you submit a query:
- It checks your permissions
- Plans the execution
- Assigns it to a warehouse
- Returns your results
The beautiful part? You never have to think about it. It just works silently in the background, making sure everything runs smoothly while you focus on your data.
Q7. How Does Snowflake Ensure High Availability?
Snowflake ensures high availability through a multi-cluster, distributed architecture designed for fault tolerance and minimal downtime. Here’s how it works:
- Multi-Cluster Shared Data Architecture – Snowflake separates compute and storage, allowing multiple compute clusters (virtual warehouses) to access the same data simultaneously without contention.
- Automatic Failover & Redundancy –
- Data Storage: All data is stored redundantly across multiple availability zones (AZs) in cloud regions, ensuring durability even if one zone fails.
- Metadata & Services Layer: Snowflake’s cloud services layer (query optimization, authentication, etc.) is distributed across AZs, automatically failing over in case of an outage.
- Continuous Data Protection –
- Time Travel: Allows recovery of data within a retention period (up to 90 days).
- Fail-Safe: Provides a 7-day backup after Time Travel expires for disaster recovery.
- Cloud Provider Resiliency – Snowflake leverages the underlying high availability features of AWS, Azure, and GCP, including cross-region replication for business-critical deployments.
- Zero Downtime Maintenance – Updates and patches are applied seamlessly without service interruption.
Q8. What Types of Cloud Platforms Does Snowflake Support?
Snowflake is a multi-cloud data platform and supports the following major cloud providers:
- Amazon Web Services (AWS) – Available across all major AWS regions.
- Microsoft Azure – Fully integrated with Azure’s ecosystem, including Azure Active Directory.
- Google Cloud Platform (GCP) – Supports all major GCP regions with seamless integration.
Snowflake ensures consistent functionality across all platforms, allowing businesses to deploy in their preferred cloud or even across multiple clouds (via data sharing).
Refernce : Supported Cloud Platforms | Snowflake Documentation
Q9. What Is a Snowflake Account in Terms of Architecture?
In Snowflake’s architecture, an account is the top-level container that holds all Snowflake objects (databases, warehouses, users, etc.). Key aspects include:
- Cloud Provider & Region Association – Each account is tied to a specific cloud (AWS, Azure, GCP) and region (e.g., AWS US-East, Azure West Europe).
- Isolated but Connected – Accounts are logically separate but can share data securely via Snowflake Data Sharing or replication.
- Resource Hierarchy – Within an account, you manage:
- Virtual Warehouses (compute resources)
- Databases & Schemas (logical data organization)
- Users & Roles (access control)
- Organization-Level Management (for Enterprises) – Multiple accounts can be grouped under a Snowflake Organization for centralized billing and governance.
Each Snowflake account operates independently but can interact with others, enabling multi-account strategies for different departments, regions, or security requirements.
Q10. How is Snowflake Different from Traditional Data Warehouses?
When we compare Snowflake to legacy systems like Oracle, Teradata, or SQL Server, it’s like comparing a smartphone to a landline – they serve similar purposes but operate in completely different ways. Here’s what makes Snowflake stand out:
1. The Great Divide: Compute and Storage Separation
In traditional systems, your processing power and data storage are locked together. Need more power? You’re forced to upgrade expensive hardware. Snowflake cuts this chain, letting you scale each independently. It’s like being able to upgrade your car’s engine without buying a whole new vehicle.
2. Smart Scaling That Doesn’t Break the Bank
Old-school warehouses are like restaurants with a fixed number of tables – when they’re full, customers wait. Snowflake operates more like a pop-up cafe that automatically adds tables when needed and removes them when the rush ends. Virtual warehouses expand and contract based on your actual needs.
3. No More Database Janitor Work
Traditional systems require constant maintenance – indexing, partitioning, vacuuming. Snowflake handles all this behind the scenes. It’s the difference between owning a vintage car that needs weekly tuning (traditional) and driving a modern electric vehicle that updates itself overnight (Snowflake).
4. Speaking the Language of Modern Data
Where older systems force you to translate JSON or XML into rigid tables, Snowflake understands these formats natively. Imagine moving from a library where all books must be rebound before reading (traditional ETL) to one where you can pick up any book and start reading immediately.
5. Pay for What You Use, Not What You Might Need
Traditional systems sell you a gym membership where you pay for 24/7 access but only go twice a week. Snowflake charges you only when you’re actually lifting weights, down to the second. No more paying for idle hardware.
6. Sharing Without the Headache
Sharing data between departments or companies used to mean making copies, sending files, and keeping everything in sync. Snowflake lets you share live data as easily as sharing a Google Doc – everyone sees the current version without creating duplicates.
7. The Best of Both Worlds Architecture
Traditional systems typically follow one of two approaches:
- Shared-Disk (like Oracle): Everyone shares one storage closet – great until everyone needs their winter coat at the same time
- Shared-Nothing (like Redshift): Each person gets their own closet, but good luck if you grow out of your assigned space
Snowflake combines the best parts of both:
- Shared storage layer acts like a magical closet that automatically makes space for everyone
- Independent compute means your neighbor’s massive query won’t leave you waiting for your turn
This hybrid approach gives you the flexibility of cloud computing without the traditional trade-offs. It’s why Snowflake can handle workloads that would choke older systems while keeping costs predictable.
The bottom line? Snowflake isn’t just another data warehouse – it’s a complete rethinking of how we store and analyze data in the cloud era. Where traditional systems force you to work around their limitations, Snowflake adapts to your needs
Q11. Understanding Shared-Disk vs. Shared-Nothing Architecture (With Real-World Examples)
1. Shared-Disk Architecture: The Company Filing Cabinet
How it works:
- All data is stored in one central location (like a giant filing cabinet)
- Multiple workers (compute nodes) access the same storage simultaneously
- Example: Oracle RAC, IBM DB2 pureScale
Real-World Example: A Hospital Patient Records System
- All patient records are stored in one central database
- Every doctor/nurse accesses the same master set of records
- If Dr. Smith in ER and Dr. Jones in Cardiology both need Mrs. Johnson’s file, they access the same storage
Pros:
✓ Simple data management (only one copy exists)
✓ Easy to maintain consistency
Cons:
✗ The central storage becomes a bottleneck (like everyone crowding around one filing cabinet)
✗ Limited scalability – adding more doctors doesn’t help if the cabinet can’t handle more requests
2. Shared-Nothing Architecture: Departmental Filing Cabinets
How it works:
- Data is partitioned across multiple independent nodes
- Each node has its own storage and processing power
- Example: Amazon Redshift, Hadoop
Real-World Example: A Retail Chain Inventory System
- Store #1 manages its own inventory database (West Region cabinet)
- Store #2 manages its own separate database (East Region cabinet)
- Corporate HQ must combine data from all stores for reporting
Pros:
✓ Excellent scalability (can add more stores easily)
✓ No single point of failure
Cons:
✗ Complex queries require moving data between nodes (like couriering inventory lists between stores)
✗ “Data skew” problems (if Store #1 gets 80% of sales, its cabinet gets overloaded while others sit idle)
Snowflake’s Hybrid Approach: The Smart Library System
Imagine a library that combines the best of both:
- All books are stored in one central automated warehouse (shared storage)
- Each librarian (compute node) can request any book instantly
- The system automatically makes temporary copies of popular books where needed
Key Advantages:
- No bottlenecks (unlike shared-disk)
- No data movement headaches (unlike shared-nothing)
- Scales seamlessly – add more librarians without reorganizing the books
This explains why Snowflake can handle complex queries across massive datasets without the traditional tradeoffs of these architectures.
Q12. What Are Fail-Safe and Time Travel in Snowflake?
Time Travel
- What it does: Allows reverting tables, schemas, or databases to a previous state within a retention period (1 to 90 days).
- Use cases:
- Accidentally deleted data? Restore it.
- Compare current vs. historical data with
ATorBEFOREclauses.
- Example: SELECT * FROM table AT(TIMESTAMP => ‘2024-05-01 12:00:00’);
Fail-Safe
- What it does: A 7-day emergency backup after Time Travel expires, managed by Snowflake (not user-accessible).
- Purpose: Protects against catastrophic failures (e.g., ransomware, corruption).
- Key notes:
- Only Snowflake support can restore from Fail-Safe.
- No additional cost, but not customizable.
Q13. How Does Snowflake’s Architecture Support Zero-Copy Cloning?
Snowflake’s unique storage layer enables instant, cost-efficient cloning without physical data duplication:
1. Metadata-Based Cloning
- When you clone a table (
CREATE TABLE CLONE), Snowflake copies only the metadata (pointers to data files), not the data itself. - Result: A clone takes seconds, regardless of size, and consumes no extra storage.
2. Copy-on-Write Mechanism
- The clone shares the original data until modified.
- Edits to the clone create new micro-partitions, leaving the original untouched.
3. Use Cases
- Dev/Testing: Clone production data without storage overhead.
- Backup Testing: Validate recovery processes quickly.
- Schema Branching: Test schema changes risk-free.
Example:
-- Clone a database for testing
CREATE DATABASE test_dev CLONE prod_db;
-- Storage remains unchanged until edits are made
Benefits:
✅ No storage costs for unmodified data.
✅ Instant creation (even for TB-scale datasets).
✅ Independent lifecycle—drops/changes to clones don’t affect the original.
Q14. What is the Difference Between X-Small and X-Large Warehouses in Snowflake?
When working with Snowflake, a virtual warehouse is your compute engine—it processes queries, transforms data, and performs analytics. The size of your warehouse determines how much power you have. Let’s break down the differences between X-Small (XS) and X-Large (XL) warehouses in simple terms.
1. Compute Power (T-Shirt Sizing)
- X-Small (XS): The smallest warehouse, like a bicycle—good for light tasks.
- 1 server cluster (single node)
- Best for:
- Simple queries
- Low-concurrency workloads (1-2 users)
- Small data processing (MBs to a few GBs)
- Cost: Cheapest, billed per second
- X-Large (XL): A powerhouse, like a freight truck—handles heavy lifting.
- 8 server clusters (8x more power than XS)
- Best for:
- Complex transformations (large joins, aggregations)
- High-concurrency workloads (dozens of users)
- Big data processing (100s of GBs to TBs)
- Cost: More expensive, but faster execution
2. When to Use Which?
- Use X-Small if:
- You’re testing queries
- Running scheduled lightweight jobs
- Don’t need fast results
- Use X-Large if:
- Queries are timing out on smaller warehouses
- Multiple users are running heavy reports
- You need results fast (e.g., dashboards for executives)
3. Scaling Flexibility
- Snowflake lets you resize warehouses on the fly (no downtime).
- Start with XS, and if a query is slow, scale up to XL instantly.
Q15. How Does Multi-Cluster Virtual Warehouse Work in Snowflake?
Snowflake’s multi-cluster warehouses are like having multiple identical teams working on the same project—if one team gets overloaded, another jumps in to help.
1. What Is a Multi-Cluster Warehouse?
- Normally, a warehouse is one cluster (group of servers).
- A multi-cluster warehouse is multiple identical clusters working together.
- Helps when many users run queries at the same time.
2. How It Works (With an Example)
Imagine a customer support dashboard used by 50 analysts:
- Single cluster (default):
- If 50 users run queries, they queue up, causing delays.
- Multi-cluster (e.g., max 4 clusters):
- Snowflake automatically spins up extra clusters when demand increases.
- Queries get distributed—no waiting!
- When traffic drops, extra clusters shut down (cost savings).
3. Key Benefits
✅ Handles high concurrency (no more query queues)
✅ Auto-scaling (no manual resizing needed)
✅ Cost-efficient (only pay for extra clusters when used)
4. When Should You Use It?
- Dashboards with many users
- ETL jobs running at the same time
- Unpredictable workloads (bursty traffic)
Final Thoughts
- X-Small vs. X-Large: Pick based on query complexity and speed needs.
- Multi-cluster: Use when many users need to query without slowdowns.
Q16. Explain Snowflake Architecture in Detail. How does it store the data and metadata in backend?
Snowflake is not built like a traditional database where everything sits inside one engine. Instead, it is designed as a layered architecture that separates storage, compute, and metadata services. This design allows it to scale up or down seamlessly, provide fast performance, and still guarantee strong consistency.
1. Storage Layer – Where the actual data lives
When you load data into a Snowflake table, it doesn’t get stored as rows in a typical relational format. Instead, Snowflake breaks it into micro-partitions, which are small, immutable chunks of data (roughly 16 MB each before compression).
- These partitions are stored in a columnar format so queries can quickly scan only the columns they need.
- The partitions are compressed and encrypted before being written.
- The files themselves are kept in the cloud provider’s object storage (Amazon S3, Azure Blob, or Google Cloud Storage).
This means that all of your raw data lives outside of Snowflake’s core engine, safely stored as optimized files in cloud storage.
2. Compute Layer – Where queries are executed
To process queries, Snowflake uses virtual warehouses, which are independent compute clusters. A warehouse fetches metadata, figures out which partitions are relevant, and then retrieves those micro-partitions from storage to execute the query.
- Warehouses are isolated from each other, so one heavy workload doesn’t slow down another.
- They can be scaled up for power or scaled out by adding more clusters.
- They don’t store data permanently — they only process it.
3. Cloud Services Layer – The control center
Sitting above both storage and compute is the Cloud Services Layer, which acts as the “brain” of Snowflake. It coordinates everything behind the scenes, including:
- Parsing and optimizing SQL queries.
- Enforcing security and user access controls.
- Managing transactions and ensuring ACID guarantees.
- Handling infrastructure tasks like scaling and billing.
- And most importantly — maintaining metadata.
The Role of Foundation DB in Snowflake
The heart of Snowflake’s metadata system is FoundationDB, an open-source, distributed key-value database. Snowflake adopted FoundationDB because it offers strong consistency and ACID transactions across a distributed environment, which is critical for a system that has to manage trillions of rows and thousands of queries at once.
Here’s what Foundation DB does for Snowflake:
- Metadata Catalog
It stores all the catalog information — databases, schemas, tables, columns, and roles. For every micro-partition created, FoundationDB keeps track of its location, size, row count, and statistics such as minimum and maximum values. - Transaction Management
When you insert new data, the warehouse writes the micro-partition to cloud storage, and at the same time, Snowflake updates metadata in FoundationDB. The update is atomic: either both the data file and metadata are committed, or neither are. - Query Optimization
Because partition statistics are stored in FoundationDB, Snowflake can decide in advance which files to read. For example, if you filter on a date column, Snowflake can instantly skip partitions outside that date range without ever scanning them. - Time Travel and Cloning
Snowflake’s features like time travel and zero-copy cloning are possible because FoundationDB stores multiple versions of metadata. Instead of copying data, Snowflake just creates new metadata pointers that reference the same micro-partitions.
Architecture with FoundationDB
Here’s how the layers connect together, showing where FoundationDB fits:
+-------------------------------------------------------------+
| Cloud Services Layer |
|---------------------------------------------------------------|
| - SQL Parsing & Optimization |
| - Security & Access Control |
| - Transaction Coordination |
| - Metadata Management (via FoundationDB) |
+-------------------------------------------------------------+
|
v
+-------------------------------------------------------------+
| FoundationDB (Metadata Store) |
|---------------------------------------------------------------|
| - Stores catalog (databases, schemas, tables, columns) |
| - Tracks micro-partition locations and statistics |
| - Manages metadata versions for cloning & time travel |
| - Ensures ACID transactions |
+-------------------------------------------------------------+
|
v
+-------------------------------------------------------------+
| Storage Layer (Cloud Object Store) |
|---------------------------------------------------------------|
| - Micro-partitions (~16 MB each, columnar, compressed)|
| - Encrypted, immutable files in S3 / Blob / GCS |
+-------------------------------------------------------------+
|
v
+-------------------------------------------------------------+
| Compute Layer (Virtual Warehouses) |
|---------------------------------------------------------------|
| - Execute SQL queries |
| - Read metadata from FoundationDB |
| - Fetch relevant micro-partitions from object storage |
| - Apply pruning and caching for fast performance |
+-------------------------------------------------------------+
Key Insight
- Data files (micro-partitions) live in cloud object storage.
- Metadata about those files lives in FoundationDB.
- Compute (warehouses) ties them together by reading metadata first, then fetching only the required files.
This architecture — powered by FoundationDB for metadata and cloud storage for raw data — is what makes Snowflake scalable, consistent, and unique compared to traditional data warehouses.